Bases para crear una API pensada para las pruebas de integración
Cuando estamos en la fase de diseño de una API, es crucial que pensemos en las pruebas desde el principio. Una buena estructura de nuestra API nos permitirá realizar pruebas de integración de manera más sencilla y efectiva.
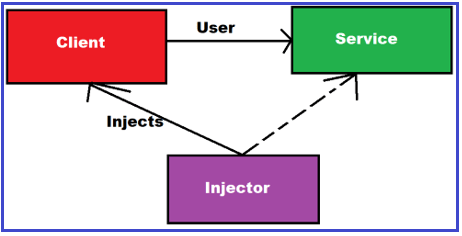
La api debería tener inyección de dependencias, para ello tenemos el principio de inversión de control (IoC). Este principio nos dice que las clases individuales no deben configurar sus dependencias por sí mismas. En su lugar, este trabajo se delega a un contenedor IoC, que se configura al inicio de la aplicación. Durante las pruebas, podemos configurar este contenedor para que proporcione versiones mock de nuestras dependencias.
Otra técnica que facilita las pruebas es el uso de métodos virtuales. Cuando un método es virtual, significa que puede ser sobrescrito en una clase derivada. Esto es muy útil en las pruebas, ya que nos permite cambiar el comportamiento de nuestros métodos y adaptarlo a nuestras necesidades de prueba.
La arquitectura del proyecto que estamos trabajando está basada en una estructura de tres capas:
- Capa de Presentación (APIs): Esta capa expone endpoints a los que los clientes pueden hacer solicitudes HTTP. Abarca controladores, acciones, filtros, etc.
- Capa de Negocio (Services): Esta es la capa que contiene toda la lógica empresarial y las reglas de validación. Es aquí donde se realiza el procesamiento de datos y se toman decisiones basadas en las reglas del negocio. Los servicios son usados por los controladores para realizar las operaciones requeridas.
- Capa de Acceso a Datos (Repository): Esta capa interactúa con la base de datos. Es responsable de crear, leer, actualizar y eliminar registros en la base de datos.
Además de la arquitectura de tres capas, estamos empleando la arquitectura limpia y la organización del código basada en características.
Arquitectura Limpia (Clean Architecture): Esta arquitectura busca separar las responsabilidades de tal manera que cada parte del código tenga un propósito bien definido. Esencialmente, se centra en la separación de las preocupaciones y en hacer que el código sea fácil de mantener y de probar. Además, permite que las partes internas de la aplicación (como la lógica de negocio y la lógica de aplicación) sean independientes de las partes externas (como la base de datos y los frameworks de UI).
Organización de código basada en características (Feature-Based): Este es un enfoque para la organización del código que agrupa el código relacionado con una característica específica juntas. En lugar de tener una estructura de directorios basada en el tipo de archivo (como controladores, modelos, vistas), tenemos una estructura de directorios basada en las características de la aplicación. Por ejemplo, todos los archivos relacionados con la entidad «Persona» se encuentran dentro de una carpeta llamada «Personas». Esta organización facilita encontrar todo lo relacionado con una característica particular y hace que el código sea más fácil de navegar y de mantener.
Finalmente, en el diseño de la aplicación se ha considerado el uso de patrones como el DTO (Data Transfer Object) para la transferencia de datos entre las capas de la aplicación y el patrón Repository para abstraer las operaciones de la base de datos.
Este diseño nos permite un buen grado de separación de responsabilidades, lo que facilita las pruebas y el mantenimiento de la aplicación.